3 Lattes
3.1 General
| Documents | Quantity |
|---|---|
| articles | 497 |
| books | 35 |
| book chapters | 87 |
| projects | 568 |
| monographs | 165 |
| master’s dissertations | 115 |
| doctoral theses | 62 |
3.2 Lattes Articles by Brazilian State
Articles with two or more authors from the same state have been normalized, only one author counts for each state.
rio::import('rawfiles/endereco3.rds') ->
endereco3
rio::import('rawfiles/artigos.rds') |>
tibble::tibble() ->
artigos
artigos |>
dplyr::left_join(endereco3) |>
dplyr::group_by(titulo_do_artigo, uf2) |>
dplyr::distinct(.keep_all = T) |>
dplyr::ungroup() |>
dplyr::count(uf2, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend = 'collection',
buttons = list(list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text = 'Download'))))## Joining with `by = join_by(id)`Papers List.
artigos |>
dplyr::select(- id, - doi) |>
dplyr::distinct(titulo_do_artigo, .keep_all = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 5,
buttons = list(list(
extend = 'collection',
buttons = list(list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text = 'Download'))))3.3 Books on Lattes
rio::import('rawfiles/livros.rds') |>
dplyr::mutate(uf2 = '') ->
livros
# rio::export(livros, 'rawfiles/livros.xlsx')
livros |>
dplyr::select(- uf2) |>
dplyr::left_join(endereco3) |>
dplyr::filter(!is.na(uf2)) |>
dplyr::group_by(titulo_do_livro, uf2) |>
dplyr::distinct(.keep_all = T) |>
dplyr::ungroup() |>
dplyr::count(uf2, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend = 'collection',
buttons = list(list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text = 'Download'))))## Joining with `by = join_by(id)`Books list.
livros |>
dplyr::select(titulo_do_livro, ano, isbn) |>
dplyr::distinct(titulo_do_livro, .keep_all = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 5,
buttons = list(list(
extend = 'collection',
buttons = list(list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text = 'Download'))))3.4 Books Chapters on Lattes
rio::import('rawfiles/capitulos_livros.rds') |>
tibble::tibble() ->
capitulos_livros
capitulos_livros |>
dplyr::left_join(endereco3) |>
dplyr::filter(!is.na(uf2)) |>
dplyr::group_by(titulo_do_capitulo_do_livro, uf2) |>
dplyr::distinct(.keep_all = T) |>
dplyr::ungroup() |>
dplyr::count(uf2, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))## Joining with `by = join_by(id)`Books Chapters list.
capitulos_livros |>
dplyr::select(titulo_do_capitulo_do_livro, ano, isbn) |>
dplyr::distinct(titulo_do_capitulo_do_livro, .keep_all = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 5,
buttons = list(list(
extend = 'collection',
buttons = list(list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text = 'Download'))))3.5 Projects on Lattes
rio::import('rawfiles/projetos.rds') |>
tibble::tibble() ->
projetos
projetos |>
dplyr::left_join(endereco3) |>
dplyr::filter(!is.na(uf2)) |>
dplyr::group_by(nome_do_projeto, uf2) |>
dplyr::distinct(.keep_all = T) |>
dplyr::ungroup() |>
dplyr::count(uf2, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))## Joining with `by = join_by(id)`Projects list.
projetos |>
dplyr::select(nome_do_projeto, ano_inicio, ano_fim) |>
dplyr::distinct(nome_do_projeto, .keep_all = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 5,
buttons = list(list(
extend = 'collection',
buttons = list(list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text = 'Download'))))3.6 Undergraduate Monographs on Lattes
rio::import('rawfiles/formacao_graduacao.rds') |>
tibble::tibble() ->
monografias
monografias |>
dplyr::count(nome_curso, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))University.
monografias |>
dplyr::count(nome_instituicao, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))State.
monografias |>
dplyr::select(id, nome_instituicao) |>
dplyr::filter(id != '') |>
dplyr::mutate(nome_instituicao = stringr::str_trim(stringi::stri_trans_general(tolower(nome_instituicao), "Latin-ASCII"))) |>
dplyr::left_join(endereco3 |> dplyr::select(- id) |> dplyr::distinct(.keep_all = T)) ->
monografias_uf## Joining with `by = join_by(nome_instituicao)`monografias_uf |>
dplyr::filter(is.na(uf2)) |>
{\(acima) rio::export(acima, 'rawfiles/monografia_nouf.xlsx')}()
rio::import('rawfiles/monografia_nouf_v2.xlsx') |>
tibble::as_tibble() |>
dplyr::filter(!is.na(uf2)) |>
dplyr::bind_rows(monografias_uf) |>
dplyr::group_by(id, nome_instituicao) |>
dplyr::distinct(.keep_all = TRUE) |>
dplyr::ungroup() |>
dplyr::count(uf2, sort = T) |>
dplyr::filter(!is.na(uf2)) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))3.7 Master’s Dissertations on Lattes
rio::import('rawfiles/formacao_mestrado.rds') |>
tibble::tibble() ->
mestrado
mestrado |>
dplyr::count(nome_curso, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 5,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))University.
mestrado |>
dplyr::count(nome_instituicao, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))State.
mestrado |>
dplyr::select(id, nome_instituicao) |>
dplyr::filter(id != '') |>
dplyr::mutate(nome_instituicao = stringr::str_trim(stringi::stri_trans_general(tolower(nome_instituicao), "Latin-ASCII"))) |>
dplyr::left_join(endereco3 |> dplyr::select(- id) |> dplyr::distinct(.keep_all = T)) ->
mestrado_uf## Joining with `by = join_by(nome_instituicao)`mestrado_uf |>
dplyr::filter(is.na(uf2)) |>
{\(acima) rio::export(acima, 'rawfiles/mestrado_nouf.xlsx')}()
rio::import('rawfiles/mestrado_nouf_v2.xlsx') |>
tibble::as_tibble() |>
dplyr::filter(!is.na(uf2)) |>
dplyr::bind_rows(mestrado_uf) |>
dplyr::group_by(id, nome_instituicao) |>
dplyr::distinct(.keep_all = TRUE) |>
dplyr::ungroup() |>
dplyr::count(uf2, sort = T) |>
dplyr::filter(!is.na(uf2)) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))3.8 Doctoral Theses on Lattes
rio::import('rawfiles/formacao_doutorado.rds') |>
tibble::tibble() ->
doutorado
doutorado |>
dplyr::count(nome_curso, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 5,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))University.
doutorado |>
dplyr::count(nome_instituicao, sort = T) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))State.
doutorado |>
dplyr::select(id, nome_instituicao) |>
dplyr::filter(id != '') |>
dplyr::mutate(nome_instituicao = stringr::str_trim(stringi::stri_trans_general(tolower(nome_instituicao), "Latin-ASCII"))) |>
dplyr::left_join(endereco3 |> dplyr::select(- id) |> dplyr::distinct(.keep_all = T)) ->
doutorado_uf## Joining with `by = join_by(nome_instituicao)`doutorado_uf |>
dplyr::filter(is.na(uf2)) |>
{\(acima) rio::export(acima, 'rawfiles/doutorado_nouf.xlsx')}()
rio::import('rawfiles/doutorado_nouf_v2.xlsx') |>
tibble::as_tibble() |>
dplyr::filter(!is.na(uf2)) |>
dplyr::bind_rows(doutorado_uf) |>
dplyr::group_by(id, nome_instituicao) |>
dplyr::distinct(.keep_all = TRUE) |>
dplyr::ungroup() |>
dplyr::count(uf2, sort = T) |>
dplyr::filter(!is.na(uf2)) |>
datatable(
extensions = 'Buttons',
rownames = F,
options = list(
dom = 'Bfrtip',
pageLength = 10,
buttons = list(list(
extend='collection',
buttons = list( list(extend = 'csv', filename = 'data'),
list(extend = 'excel', filename = 'data')),
text='Download'))))3.9 Articles - collaboration network among states
artigos |>
dplyr::left_join(endereco3) |>
dplyr::arrange(titulo_do_artigo) |>
dplyr::filter(!is.na(uf2)) |>
dplyr::group_by(titulo_do_artigo, uf2) |>
dplyr::distinct(.keep_all = T) |>
dplyr::ungroup() ->
artigos3## Joining with `by = join_by(id)`artigos3 |>
dplyr::group_by(titulo_do_artigo) |>
dplyr::group_indices(titulo_do_artigo) ->
artigos3$pmk ## Warning: The `...` argument of `group_indices()` is deprecated as of dplyr 1.0.0.
## ℹ Please `group_by()` first
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.artigos3 |>
dplyr::arrange(pmk) ->
artigos3
artigos3 |> dplyr::select(pmk, uf2) |> dplyr::arrange(pmk) -> temp
temp2 <- split(temp, f = temp$pmk)
temp2 <- lapply(temp2, function(x) {as.character(x$uf2)})
idv <- temp2
temp2 <- lapply(temp2, function(x) {expand.grid.unique(x, x, include.equals = F)})
temp2 %>>%
dplyr::bind_rows() %>>%
(aggregate(list(weight = rep(1, nrow(.))), ., length)) %>>%
(dplyr::arrange(., - weight)) %>>%
(tibble::as_tibble(.) -> ide)
idv <- unlist(idv)
idv2 <- idv[!duplicated(idv)]
names(idv2) <- NULL
artigos3 %>>%
dplyr::count(uf2, name = 'qtde_artigos') %>>%
dplyr::rename(name = uf2) %>>%
(. -> aa)
graph.data.frame(ide, directed = FALSE, vertices = idv2) %>>%
(as_tbl_graph(.) -> net)## Warning: `graph.data.frame()` was deprecated in igraph 2.0.0.
## ℹ Please use `graph_from_data_frame()` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.net %>>%
activate(nodes) %>>%
left_join(aa) %>>%
tidygraph::activate(nodes) %>>%
dplyr::filter(!is.na(qtde_artigos)) %>>%
dplyr::filter(name != 'Brasil') %>>%
dplyr::mutate(id = name) %>>%
(. -> net)## Joining with `by = join_by(name)`V(net)$estado <- gsub('Brasil_', '', (V(net)$name))
import('rawfiles/sigla_estados.csv') |>
tibble::as_tibble() |>
dplyr::mutate(regiao_id = str_sub(co_uf, 1, 1)) |>
dplyr::select(estado = sigla_uf, regiao, regiao_id) ->
bb
net %>>%
activate(nodes) |>
left_join(bb) |>
dplyr::mutate(regiao = ifelse(is.na(regiao), 'Exterior', regiao)) |>
dplyr::mutate(regiao_id = ifelse(is.na(regiao_id), 6, regiao_id)) ->
net## Joining with `by = join_by(estado)`write_graph(net, file = 'networks/netocuf.net', format = c("pajek"))
writePajek(V(net)$qtde_artigos, 'networks/netocuf_qtde.vec')
writePajek(V(net)$regiao_id, 'networks/netocuf_regiao.clu')VosViewer - Fractionalization - Attraction 6 Repulsion 1
Colors of the nodes per region of Brazil, or foreign country. Size of the node per quantity of articles per region.
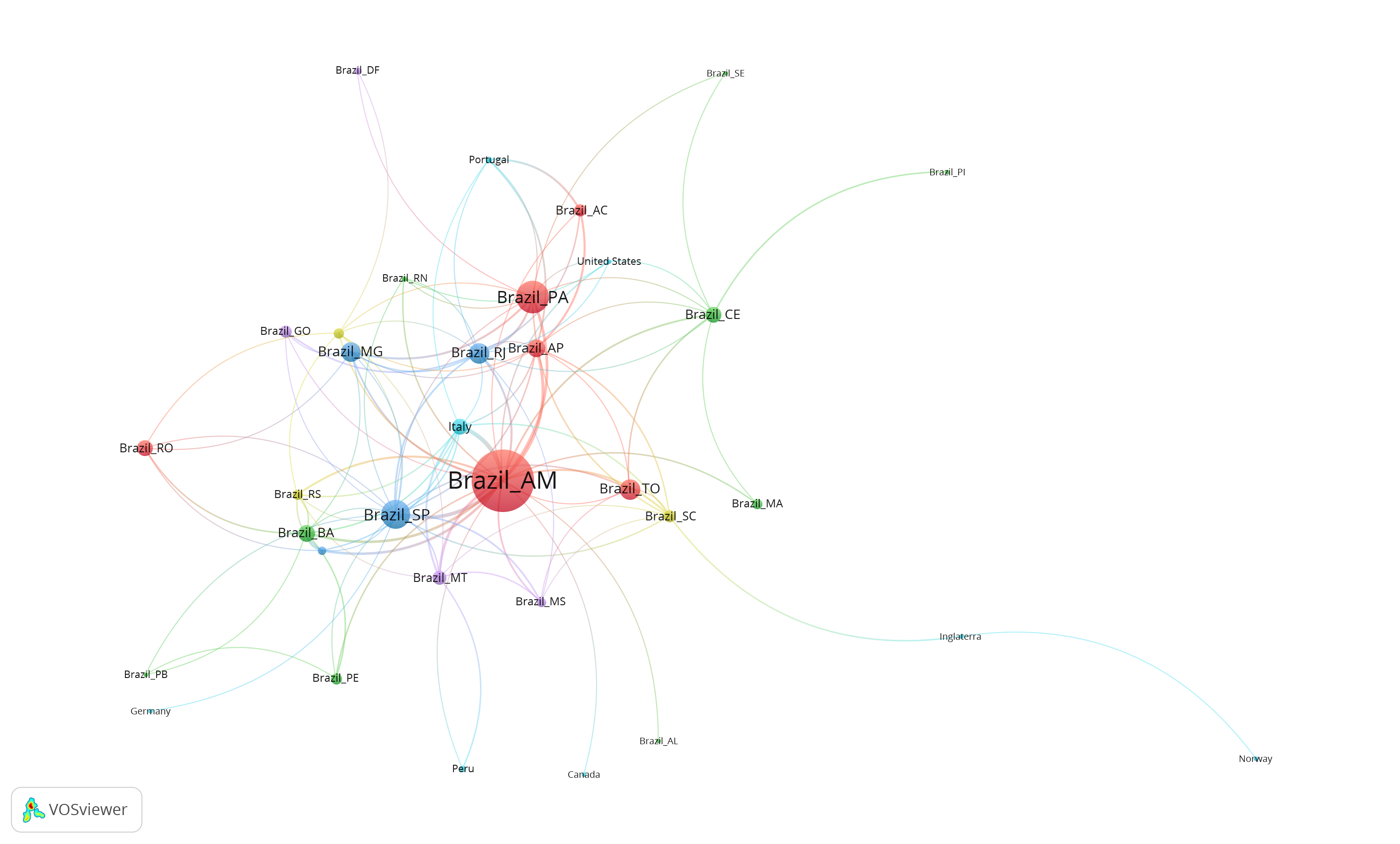
3.10 Articles - author collaboration network
artigos |>
dplyr::left_join(endereco3) |>
dplyr::arrange(titulo_do_artigo) |>
dplyr::filter(!is.na(uf2)) |>
dplyr::group_by(titulo_do_artigo, uf2) |>
dplyr::distinct(.keep_all = T) |>
dplyr::ungroup() ->
artigos3## Joining with `by = join_by(id)`artigos3 |>
dplyr::group_by(titulo_do_artigo) |>
dplyr::group_indices(titulo_do_artigo) ->
artigos3$pmk ## Warning: The `...` argument of `group_indices()` is deprecated as of dplyr 1.0.0.
## ℹ Please `group_by()` first
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.artigos3 |>
dplyr::arrange(pmk) ->
artigos3
artigos3 |> dplyr::select(pmk, id) |> dplyr::arrange(pmk) -> temp
temp2 <- split(temp, f = temp$pmk)
temp2 <- lapply(temp2, function(x) {as.character(x$id)})
idv <- temp2
temp2 <- lapply(temp2, function(x) {expand.grid.unique(x, x, include.equals = F)})
temp2 %>>%
bind_rows() %>>%
(aggregate(list(weight = rep(1, nrow(.))), ., length)) %>>%
(arrange(., - weight)) %>>%
(as_tibble(.) -> ide)
idv <- unlist(idv)
idv2 <- idv[!duplicated(idv)]
names(idv2) <- NULL
artigos3 %>>%
count(id, name = 'qtde_artigos') %>>%
rename(name = id) %>>%
(. -> aa)
graph.data.frame(ide, directed = FALSE, vertices = idv2) %>>%
(as_tbl_graph(.) -> net)
rio::import('rawfiles/dados_gerais.rds') |>
dplyr::select(name = id, citar_como = nome_em_citacoes_bibliograficas, nome_completo) |>
dplyr::mutate(citar_como = gsub(';.*$', '', citar_como)) ->
citar_como
net %>>%
activate(nodes) %>>%
dplyr::left_join(aa) %>>%
tidygraph::activate(nodes) %>>%
dplyr::filter(!is.na(qtde_artigos)) %>>%
dplyr::left_join(citar_como) %>>%
dplyr::left_join(endereco3 |> dplyr::select(name = id, uf2)) %>>%
dplyr::rename(id = citar_como) %>>%
(. -> net)## Joining with `by = join_by(name)`
## Joining with `by = join_by(name)`
## Joining with `by = join_by(name)`net %>>%
activate(nodes) |>
dplyr::mutate(estado = gsub('Brasil_', '', uf2)) |>
left_join(bb) |>
dplyr::mutate(regiao = ifelse(is.na(regiao), 'Exterior', regiao)) |>
dplyr::mutate(regiao_id = ifelse(is.na(regiao_id), 6, regiao_id)) ->
net## Joining with `by = join_by(estado)`net |>
activate(nodes) |>
dplyr::filter(qtde_artigos > 3) ->
net
# write_graph(net, file = 'networks/netcolaut.net', format = c("pajek")) # sobrenomes normalizados na mão
writePajek(V(net)$qtde_artigos, 'networks/netcolaut_qtde.vec')
writePajek(V(net)$regiao_id, 'networks/netcolaut_regiao.clu')VosViewer - Association Strength - Attraction 6 Repulsion 0

Colors of the regions:
- Cluster 1 = Norte
- Cluster 2 = Nordeste
- Cluster 3 = Sudeste
- Cluster 4 = Sul
- Cluster 5 = Centro-Oeste
- Cluster 6 = Exterior