3 Green Finance [coupling]
Query applied on Scopus:
3,663 document results
TITLE-ABS-KEY ( ( finance OR financial ) W/3 ( green OR climate OR carbon OR sustainable ) ) AND
( LIMIT-TO ( DOCTYPE , "ar" ) OR LIMIT-TO ( DOCTYPE , "ch" ) OR LIMIT-TO ( DOCTYPE , "re" ) OR
LIMIT-TO ( DOCTYPE , "bk" ) ) AND ( LIMIT-TO ( SRCTYPE , "j" ) ) Downloaded in September 2021.
3.1 Growth rate
## 'r2()' does not support models of class 'nls'.| Papers | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| b0 | 1.262 | 0.444 – 2.080 | 0.004 |
| b1 | 0.201 | 0.178 – 0.224 | <0.001 |
| Observations | 31 | ||
- Growth Rate 22%
- Doubling time 3.4 Years
3.2 Growth rate - Scopus
## 'r2()' does not support models of class 'nls'.| Papers | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| b0 | 4.700 | 4.484 – 4.915 | <0.001 |
| b1 | 0.053 | 0.051 – 0.055 | <0.001 |
| Observations | 31 | ||
- Growth Rate 5.5%
- Doubling time 13 Years
3.3 Network
Bibliographic coupling was chosen, because it focuses on the most recent papers.
![Bibliographic Coupling [Shibata et al (2009)]](images/met-2009-Shibata-et-al.png)
Figure 3.1: Bibliographic Coupling [Shibata et al (2009)]

3.11 Hubs per group
- TC = Scopus times cited
- Ki = Network citations
- ki = Group citations
- Zi = The within-group degree \(z_i\) measures how ‘well-connected’ article \(i\) is to other articles in the group [\(z_i \geq 2.5\) Hub]
- Pi = Measures how ‘well-distributed’ the links of article \(i\) are among different groups. [higher \(=\) citations better distributed between groups]
- zone = \(R5\) provincial hubs; \(R6\) connector hubs; \(R7\) kinless hubs
- TI = Title
- DI = DOI
- AB = Abstract
- DE = Keywords
3.12 Topic Modeling
Wikipedia description:
In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents. Topic modeling is a frequently used text-mining tool for discovery of hidden semantic structures in a text body.
STM - Structural Topic Modeling (Roberts, Stewart e Airoldi, 2016)
- allow to use document metadata to improve classification
STM is a new version of famous LDA (Blei, 2012)
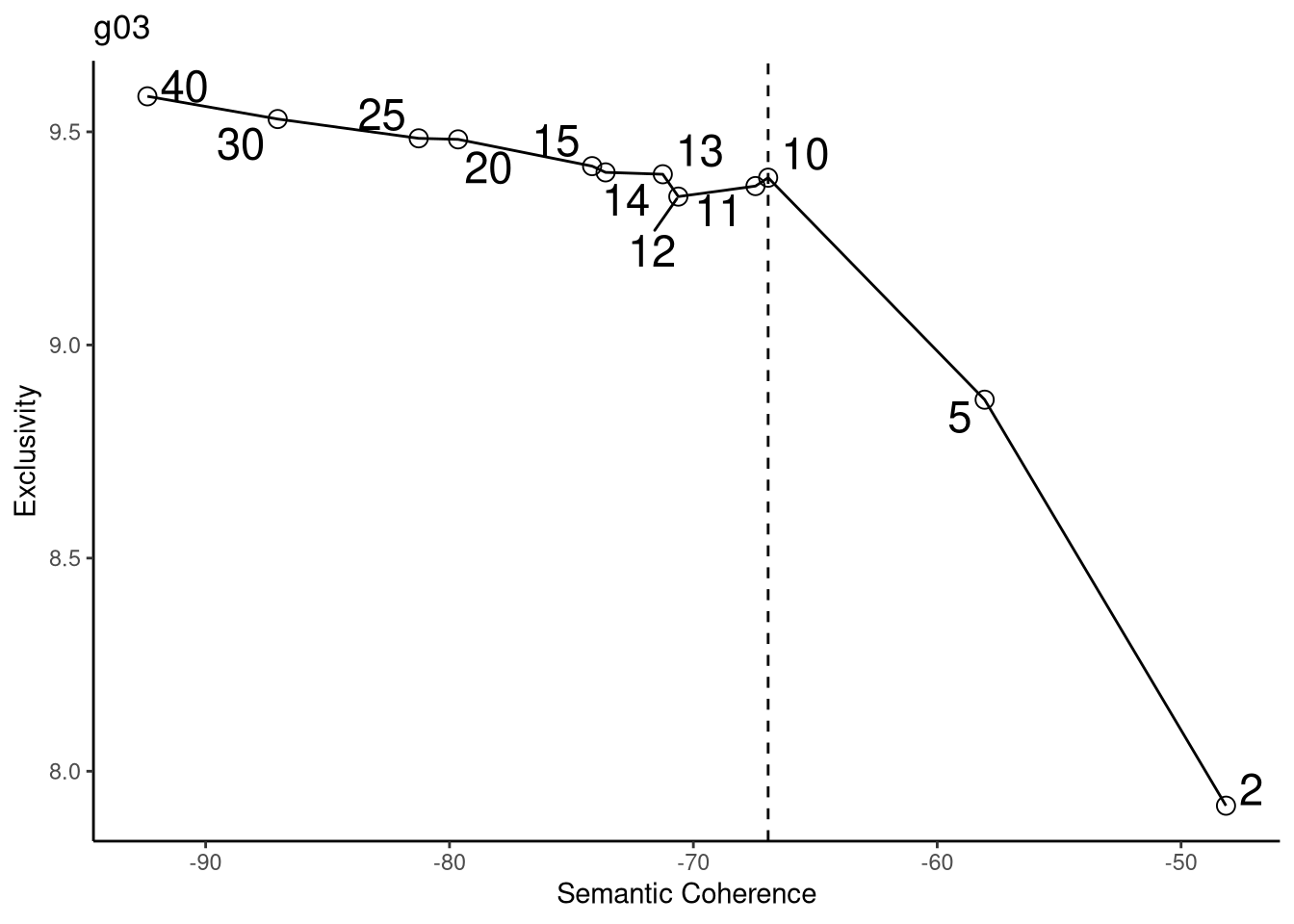
Define the number of topics (Kim, Lee e King, 2020):
semantic coherence reflects the fact that high-probability terms of a topic tend to occur together across documents under analysis (Roberts, Stewart e Airoldi, 2016).
exclusivity of topic terms dictates that high-probability terms in one topic should not overlap with high-probability terms in other topics, and that high-probability terms be unique and exclusive to one topic only (Bischof e Airoldi, 2012).
Other works on topic modeling: Kuhn (2018), Chen, Zou, et al. (2020), Chen, Chen, et al. (2020), Hsu et al. (2019), Lee et al. (2020), Qian et al. (2021), Ranaei et al. (2019), Tontodimamma et al. (2020).
Kuhn (2018) also chose the number of topics using the same type of graph generated here.
3.12.1 g01
## Building corpus...
## Converting to Lower Case...
## Removing punctuation...
## Removing stopwords...
## Removing numbers...
## Stemming...
## Creating Output...## Removing 6215 of 8521 terms (10127 of 117224 tokens) due to frequency
## Your corpus now has 1315 documents, 2306 terms and 107097 tokens.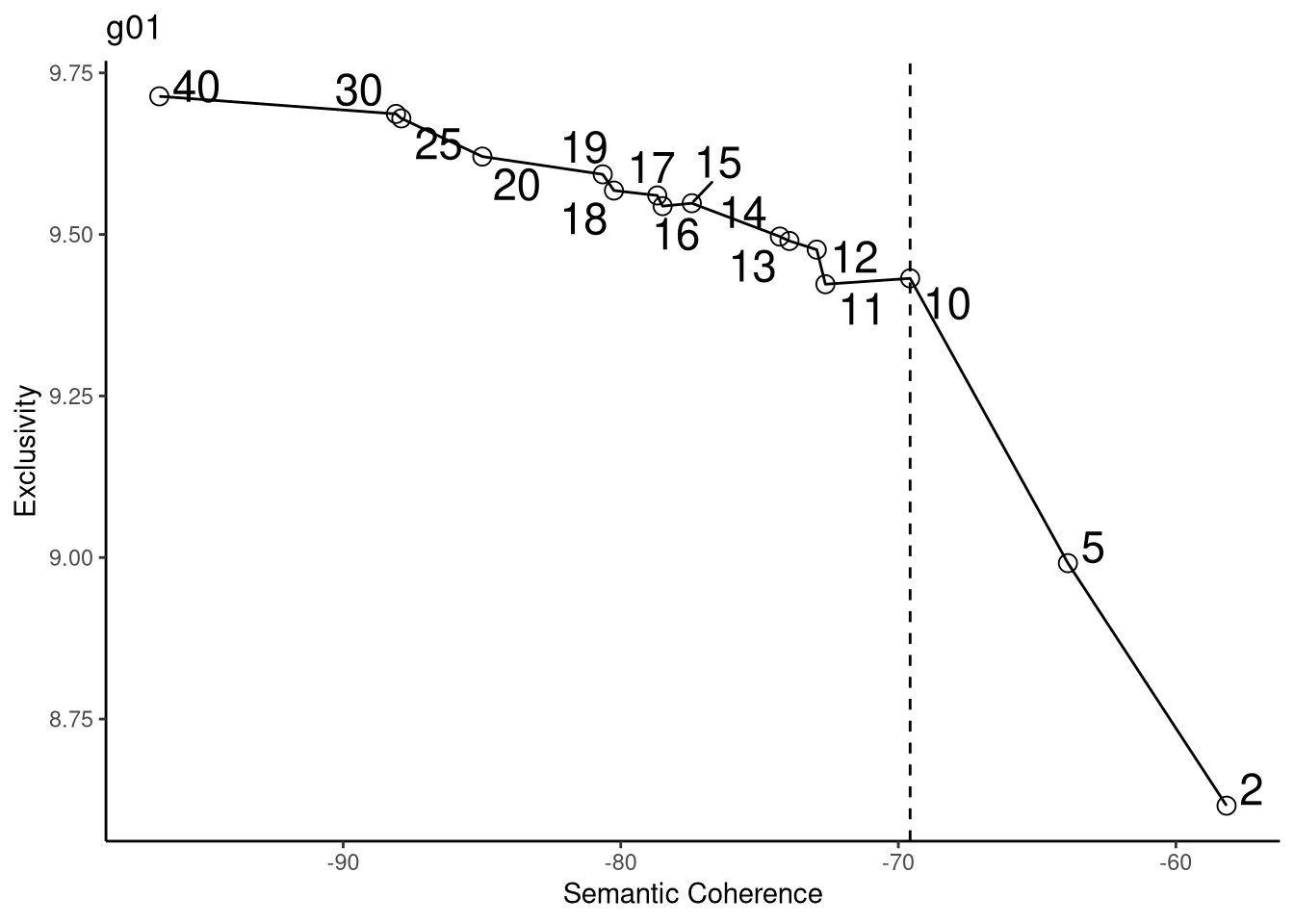
3.12.2 g02
## Building corpus...
## Converting to Lower Case...
## Removing punctuation...
## Removing stopwords...
## Removing numbers...
## Stemming...
## Creating Output...## Removing 5875 of 8048 terms (9540 of 111152 tokens) due to frequency
## Your corpus now has 1187 documents, 2173 terms and 101612 tokens.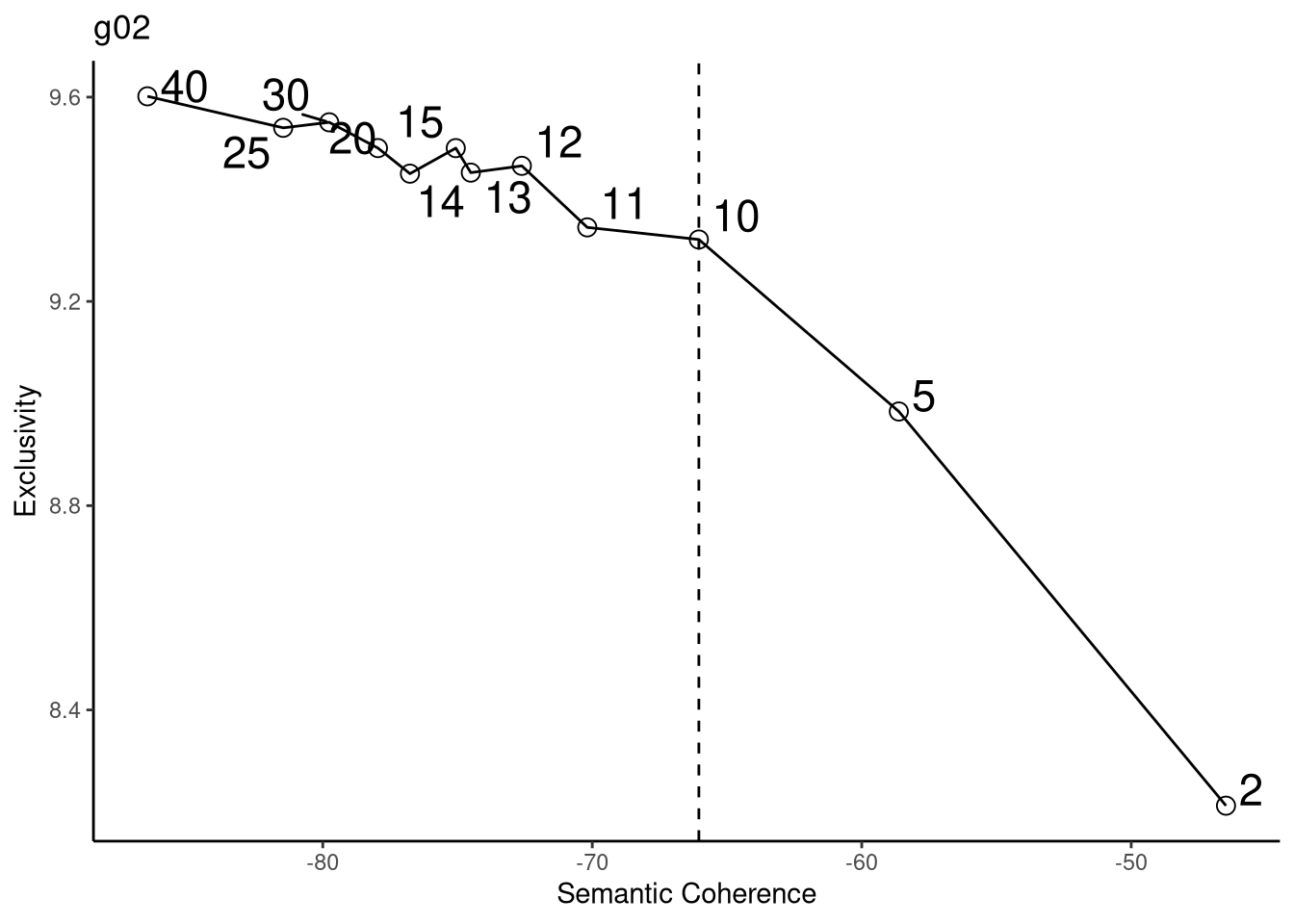
3.12.3 g03
## Building corpus...
## Converting to Lower Case...
## Removing punctuation...
## Removing stopwords...
## Removing numbers...
## Stemming...
## Creating Output...## Removing 3518 of 5021 terms (6138 of 61907 tokens) due to frequency
## Your corpus now has 757 documents, 1503 terms and 55769 tokens.